1、文章信息:
IEEE TRANSACTIONS ON MOBILE COMPUTING,CCF-A
2、文章概述
2.1、文章思想
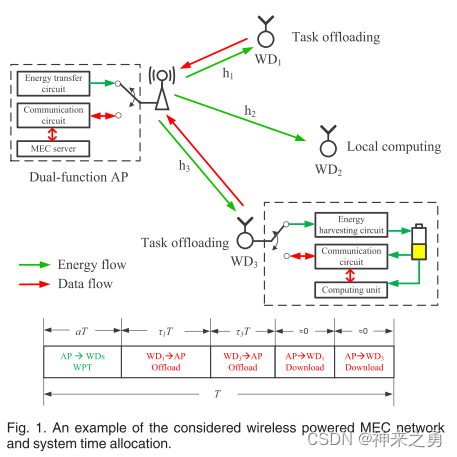
本文考虑了一个具有AP和多个WD的无线供电MEC网络,如图所示:
 编辑
编辑
每个WD遵循二进制卸载策略(即要么全部卸载要么全部本地执行)。本文的目标是联合优化每个WD的任务卸载决策、WPT(无线供电传输)和任务卸载之间的传输时间分配,以及根据时变的无线信道进行多个WD之间的时间分配。
基于此,作者提出了一个在线卸载框架(DROO),以最大化所有WD计算速率的加权和(单位时间内处理的比特数)。与现有整数规划和基于学习的方法相比有以下贡献:
- 提出的DROO框架学习过去的卸载策略,在时变无线信道条件下自动更改策略。(完全消除了解决MIP问题的必要,避免了随着数据量增多而造成的计算复杂度爆炸)【为什么具有高复杂性】
- 与深度学习方法不同,DROO将原始问题分解为卸载策略子问题与资源分配子问题,不需要离散化的信道增益,避免了维数灾难问题
- 为了高效地生成卸载动作,设计了一种新颖的保序动作生成方法。具体而言,它只需要从少量候选动作中进行选择,因此在具有高维动作空间的大规模网络中具有计算可行性和高效性。同时,它还提供了生成动作的高多样性,并且比传统的动作生成技术具有更好的收敛性能。
- 开发了一种自适应程序,能够动态地调整DROO算法的参数。具体而言,它逐渐减少在一个时间段内需要解决的凸资源分配子问题的数量。这有效地降低了计算复杂度,同时不会影响解决方案的质量。
2.2、related work
在DQN方法中,作者基于离散化的信道增益作为输入向量,因此在需要高信道量化精度时遭受维数灾难和缓慢收敛。
此外,在每次迭代过程中的决策穷举性质,DQN不适合处理高维动作。
3、主体部分
3.1、系统建模
1)假设WPT和communication是在同一频段执行,在每个设备处实现TDD(时分复用电路)避免WPT与communication之间相互干扰。
2)假设信道互逆(即上行链路与下行链路的信道增益是相同的)
3)系统时间被划分为连续的等长时间帧T(设置为小于信道相干时间(信道保持稳定的最长时间))
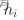 编辑
编辑
标记的时间帧处AP与第i个WD之间的无线信道增益(用于评估信号传输的质量和通信速率)
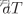 编辑
编辑
用于WPT的时间,a ∈[0,1] ,其中AP广播RF能量以供WD收集
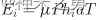 编辑
编辑
表示第i个WD收获的能量值,其中μ表示能量收集效率,P表示AP发射功率
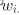 编辑
编辑
第i个WD的权重,权重越大,分配给WD的计算速率越大
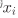 编辑
编辑
代表卸载策略,枚举值(0,1),0代表本地执行; 1代表卸载到AP
3.2、本地计算模型
本地计算模式下的WD可以同时收集能量和执行计算任务。
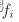 编辑
编辑
处理器的计算速度(每秒的周期数)
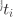 编辑
编辑
表示代表计算时间
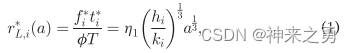 编辑
编辑
本地计算速率(以比特每秒为单位)
T:等长时间帧,φ表示处理一位任务数据所需的周期数
3.3、边缘计算模型
由于TDD约束,处于卸载模式的WD只能在收获能量之后将其任务卸载到AP。
要下载到WD的计算反馈比卸载到AP的数据短得多,所以完全忽略AP在任务计算和下载上花费的时间。
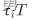 编辑
编辑
第i个WD的卸载时间,前者取值[0,1]
为了最大化计算速率,执行任务卸载的WD会耗尽其收获能量来执行任务卸载,则计算速率等于其数据卸载能力:
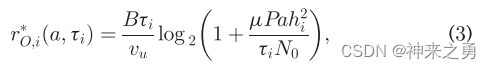 编辑
编辑
B代表通信带宽、N代表接收机噪声功率。
3.4、问题表述
在标记的时间帧中无线供电MEC网络的加权和计算速率被表示为:
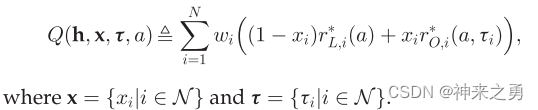 编辑
编辑
则本文目的便是:
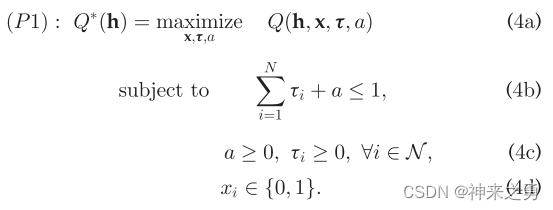 编辑
编辑
可见P1是一个混合整数规划非凸问题,但是一旦给定x,则P1可以简化为以下凸问题:
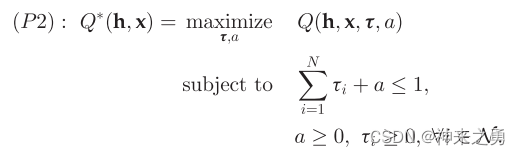 编辑
编辑
则将问题P1分解为两个子问题:
- 卸载决策:需要在2的N次方个可能的卸载决策中搜索到较好的卸载决策x
- 资源分配:关于凸问题P2的最优时间分配可以高效解决,例如,在相关对偶变量上使用一位二分搜索,其时间复杂度在O(N)内
4、DROO算法
 编辑
编辑
4.1、算法概述
旨在设计一个卸载策略函数Π,一旦在每个时间帧的开始给定信道增益h,就可以快速生成一个最优卸载策略x
 编辑
编辑
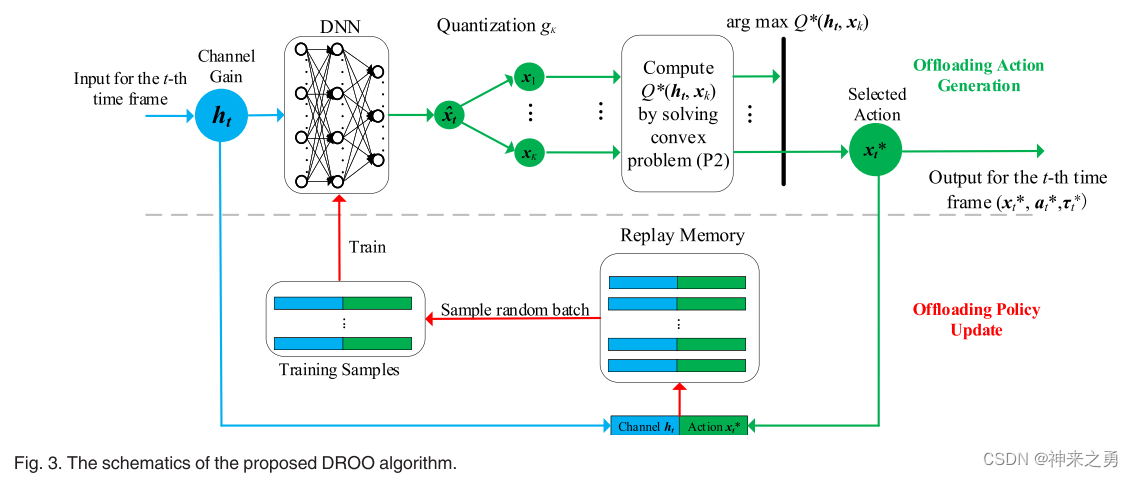
所提出的DROO算法会从经验中逐渐学习这样的策略函数Π
 编辑
编辑
算法结构图如图所示,由交替的两阶段组成:Offloading Action Generation 和 Offloading Policy Update
卸载动作的生成是基于DNN的使用,该DNN将信道增益h作为输入,基于卸载策略Π(由θ参数化)输出卸载动作x
猜测:使用DNN生成卸载策略,然后将卸载策略量化为K个离散的卸载决策选项,使用二进制编码表示每个选项的状态。 然后选取所选动作致使P2问题最大化的x,基于input的h组成训练样本加入经验回访池中。
卸载策略更新:从经验回放池中随机选取batch个随机样本训练DNN,DNN将其参数更新。以此类推以更新策略
4.2、Offloading Action Generation(没看懂)
在第一个时间帧时,DNN的参数θ被随机初始化(零均值正态分布)。
- 那么DNN首先输出一个宽松计算卸载动作x,该动作是由参数化函数表示的
逼近定理:如果在神经元处应用适当的激活函数,则具有足够隐藏神经元的一个隐藏层足以逼近任何函数映射f
- 通过量化函数将DNN输出的动作x量化为K个二进制卸载动作(K是一个设计参数),量化函数gk如下:
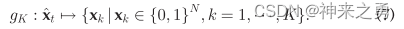 编辑
编辑
此处,K可以是1到2的N次方中的任意整数,越大的K可以获得越好的解质量但是会有更大的计算复杂度,这里作者提出了一种保序量化方法用来平衡质量与复杂度之间的关系。
其基本思想是:量化期间保持排序。
4.3、卸载策略更新
此处使用经验重放技术
(参考文献如下:(可重用)
Human-level control through deep reinforce-ment learning
Reinforcement learning for robots using neuralnetworks)
DNN的参数使用Adam算法来更新,以减少平均交叉熵损失
DNN迭代的从最佳状态动作对中学习,随着时间推移产生更好的状态动作对。同时在有限存储器空间约束情况下(状态动作对会不断使用FIFO策略更新),DNN仅从最近最优生成的的数据样本中学习。这种闭环强化学习机制不断改进其卸载策略,直到收敛。
 编辑
编辑
4.4、K的自适应设置
DROO算法设计的优势在于其消除了求解困难MIP问题的需要,从而降低了计算复杂度。在该算法中其主要计算复杂度在于求解P2问题以获取K个动作中最佳卸载动作。
这里越大的K会导致在每个时间帧中更好的卸载决策,也因此会有更好的卸载策略,所以设置K的时候会有一个基本的计算复杂度——性能之间的权衡。
作者提出了一个自适应过程,自动调整由保序量化方法产生的量化动作的数量。
(未细看)
5、实验结果
5.1、收敛性能
5.2、更新间隔的影响
5.3、计算速率性能
5.4、执行延迟
6、结论
本文中作者基于深度强化学习提出了在线卸载算法DROO,以最大限度地提高无线供电MEC网络中的加权和计算率与二进制计算卸载。该算法从过去卸载经验中学习,通过强化学习改善其由DNN产生的卸载行为。并通过保序量化方法和自适应参数设置方法加速算法收敛。其提出的方法与传统方法相比,避免了解决MIP问题的需要,仿真结果表明DROO实现了接近最优的性能(和现有的基准方法相比),但却减少了CPU执行延迟超过一个数量级,使得在无线衰落环境中无线供电MEC系统的实时性变得真正可行。
本文的挑战在于,该DROO框架适用于一般MEC网络,当对象是移动的WD时将会导致DROO更难收敛。猜测原因在于WD的移动性造成信号不稳定、影响卸载到服务器的时间?
未来笔者希望DROO可以用来解决设计耦合整数决策和连续资源分配问题的无线通信和网络中的各种MIP问题,例如,D2D通信中的模式选择、蜂窝系统中的用户到基站关联、无线传感器网络中的路由以及无线网络中的缓存放置。


